Reference
- Python 공식 문서 - textwrap - Text wrapping and filling
- ‘wrap’ 사전적 의미 - Cambridge Dictionary
- ‘text wrap’의 뜻 - webopedia.com
- ‘wrap text’의 뜻 - computerhope.com
- ‘word wrap’의 뜻 - webopedia.com
(PYTHON) Day - 7 Strings에서 textwrap 패키지 를 사용하는 문제가 있었습니다. 뭔가 용어에 대해 정확히 이해하고 넘어가야 해당 기능이 필요할 때 기억해내고 사용할 것 같아서 아래에 정리해 두려고 합니다.
Wrap?
Image Search


Google에 ‘wrap’이라는 단어를 이미지로 검색해보면 왼쪽 사진과 같은 음식 사진들로 가득찬 것을 보실 수 있습니다.
한국어로 ‘랩’이라고 검색하면 오른쪽 사진과 같은 비닐랩 사진이 많이 보이지만 비교적 다양한 사진들이 섞여 있습니다.
많은 사람들이 wrap이라는 단어를 들었을 때 음식이나 주방요품을 떠올리면서 무언가를 감싸는 의미를 갖는 다는 느낌을 받습니다.
Cambridge Dictionary
[Verb]
to cover or surround something with paper, cloth, or other material
to cover someone with a piece of material in order to protect them
영어사전에서 찾아봐도 위에서 예상한 것 처럼 ‘무언가를 감싸는 것’을 뜻한다는 것을 볼 수 있습니다.cover, surround 라는 단어에서 ‘덮는다’, ‘감싼다’라는 의미를 정확히 알 수 있는데, protect 라는 단어가 눈에 띄는군요.
Text Wrap?
‘text wrap’은 ‘plastic wrap’처럼 텍스트로 무언가를 감싸는 것을 뜻하는 것일까요?
Image Search



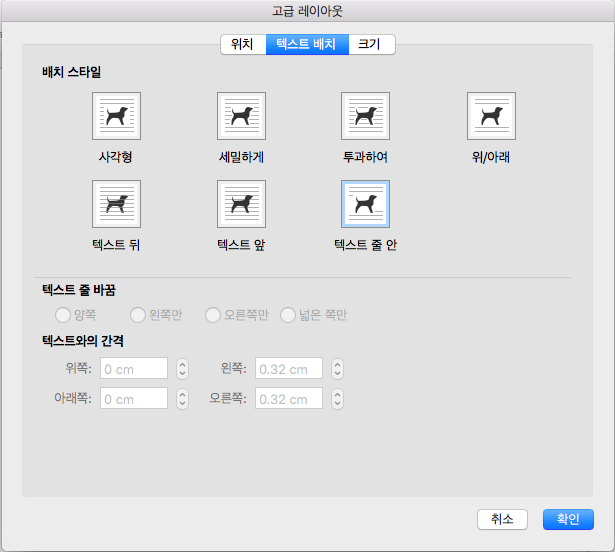
똑같이 Google 이미지 검색으로 ‘text wrap’을 찾아보면 위 사진처럼 특정 이미지에 맞춰 그 주위를 텍스트로 감싸는 것을 볼 수 있습니다. 이런 기능을 우리는 문서 작성 프로그램을 사용하며 자주 볼 수 있습니다. 한글로는 ‘텍스트 배치’라고 적혀있고 영어로 ‘text wrapping’이라고 적혀있는 것을 아래 사진을 통해 확인할 수 있습니다.
Webopedia
문득 Webo는 무엇을 뜻하는지 궁금해졌다. 백과사전을 뜻하는 Encyclopedia은 그리스어 Enkyklios Paideia(Complete Knowledge)에서 온 말이다. 이를 응용해서 Wikipedia는 wiki(인터넷 사용자 누구나 작성하고 수정할 수 있는) + pedia(지식)를 합친 뜻이 된다. 그렇다면 webo는 무슨 뜻이 있을까? 그냥 webpedia해도 되지않나? 왜 o가 들어갔지?
(본문의 내용을 요약한 것입니다. 정확한 내용은 위 출처를 통해 확인하실 수 있습니다.)
텍스트가 그래픽(이미지, 도표 등)을 감싸고 있는 것
HTML에서 <img> tag 안에 align=’left’ 혹은 ‘right’ 등을 선언함으로 텍스트 배치를 사용할 수 있다
동의어로 text flow 가 있다
하지만 문제에서 봤던 기능은 여기까지 알아본 내용과는 다른 것 같습니다. Python의 textwrap 패키지는 문단의 여백을 제어하는 기능인 것 같아서 조금 더 알아보겠습니다.
Wrap Text??
단어의 순서를 바꿔서 ‘wrap text’는 무언가로 텍스트를 감싸는 것을 뜻하는 것일까요?
Image Search
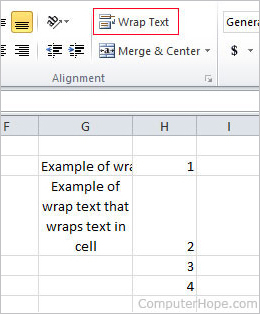

word, 한글과 같은 문서 작성 프로그램과는 다르게 Excel과 같은 spreadsheet 프로그램에서는 ‘wrap text’라는 기능을 제공합니다. 첫번째 사진에서 볼 수 있듯이 해당 기능은 텍스트를 셀 크기에 맞춰서 줄 바꿈을 실행합니다.
Webopedia
정해진 margin에 맞춰 강제로 텍스트의 형태를 바꾸는 것
동의어로 word wrap 이 있다
개인적으로 wraptext 혹은 wordwrap가 올바른 패키지 이름이지 않을까 하고 생각합니다. 왜 textwrap이 이름으로 채택되었는지 더 깊이 파고들지는 않겠습니다.