지난 Hexo 블로그에 Google Adsense 설정_1 에 이어 설정하는 방법에 대해 알아보겠습니다.
지난 시간
지난 7월 17일 Google Adsense를 신청 했었고 일반적으로 3일 정도 걸린다는 안내와는 다르게 10일이나 걸렸습니다. 승인이 늦게 나는 이유에 대해서는 여러 추측들이 있는 것 같지만 저는 앞선 포스트에서 알려드렸던 설정 외에는 건드린 것이 없고 그저 그 후로도 계속해서 새로운 글을 작성했습니다. 아마 저의 경우 게시글 수가 조금 부족했던 것이 그 이유가 아니였나 하고 생각해봅니다.

Google Search Console이 2018년 1월에 리뉴얼 되었듯이 Google Adsense 또한 조금 새롭게 바뀐 것 같았습니다. 처음 등록해보는 거라 미흡한 부분들이 있을 수도 있지만 제가 사용하는 Hexo_Next_Theme 에 직접 적용하며 하나씩 알아가 보겠습니다.
기본 광고 설정
- 메일의 시작하기 버튼을 클릭하거나 직접 Google Adsense 웹페이지에 접속하게 되면 아래 창을 만나게 됩니다.

- 빠르게 광고 설정을 클릭하여 다음 화면으로 진행하도록 합니다.

- 이전에는 머신러닝을 활용한 자동 광고 생성이 없었던 것 같은데 사용자의 편의를 위해 새롭게 이 기능을 제공하는 것 같습니다.
그보다 상단의 붉은 경고가 눈에 띄는군요.

- ads.txt 라는 파일에 대해 잘 모르기 때문에 자세히 알아보기 버튼을 클릭해 보겠습니다.

- 실공급원과 부정적인 공급원을 구분하고 광고 소스를 목록화 하여 손해를 보지 않게 도와주는 텍스트 파일인 것 같습니다. 권장사항이지만 한다고 손해볼 것도 없으니 등록하도록 하겠습니다.
위 안내글에서 언급되었듯이 직접 애드센스용 ads.txt를 생성할 수도 있지만, 앞선 붉은 경고문에서 지금 해결하기 버튼을 클릭하고 쉽게 다운받으실 수도 있습니다.
(직접 작성하실 경우, 게시자 ID 는 Adsense 홈페이지 -> 계정 -> 설정 -> 계정 정보에 있습니다.)

- 이렇게 직접 작성하거나 다운받은 ads.txt 파일을 블로그 테마의 source 폴더에 넣어 주시면 됩니다. (e.g
hexo/themes/next/source)
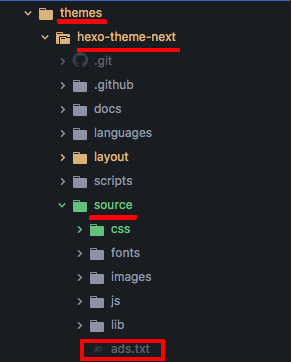
hexo g -d를 통해 새롭게 추가한 파일을 블로그에 배포하시면 됩니다. 구글 크롤링 봇의 주기가 24시간이라고 하니, 아마 다음날 해당 문제는 해결될 것 같습니다.
자동 광고 설정
- 설명을 먼저 읽어보도록 하겠습니다.
- 사용자가 조금 더 콘텐츠에 집중할 수 있도록 항상 광고가 게시되는 것이 아니라 머신러닝 학습으로 최적의 순간(아마 조회수가 많은 포스트에 게시되지 않을까요?)에만 광고가 게시되는 것 같습니다.
- 아직 방문자도 없고…ㅠ 광고가 게시되는 것을 직접 확인하고 싶어서 자동 광고는 다음으로 미룰까 했었는데 아래의 내용을 보고 적용하기로 결심했습니다.

- 즉, 수동으로 광고를 게제한 것과는 별개로 작동하는 것 같아 우선 자동 광고를 적용해보겠습니다.
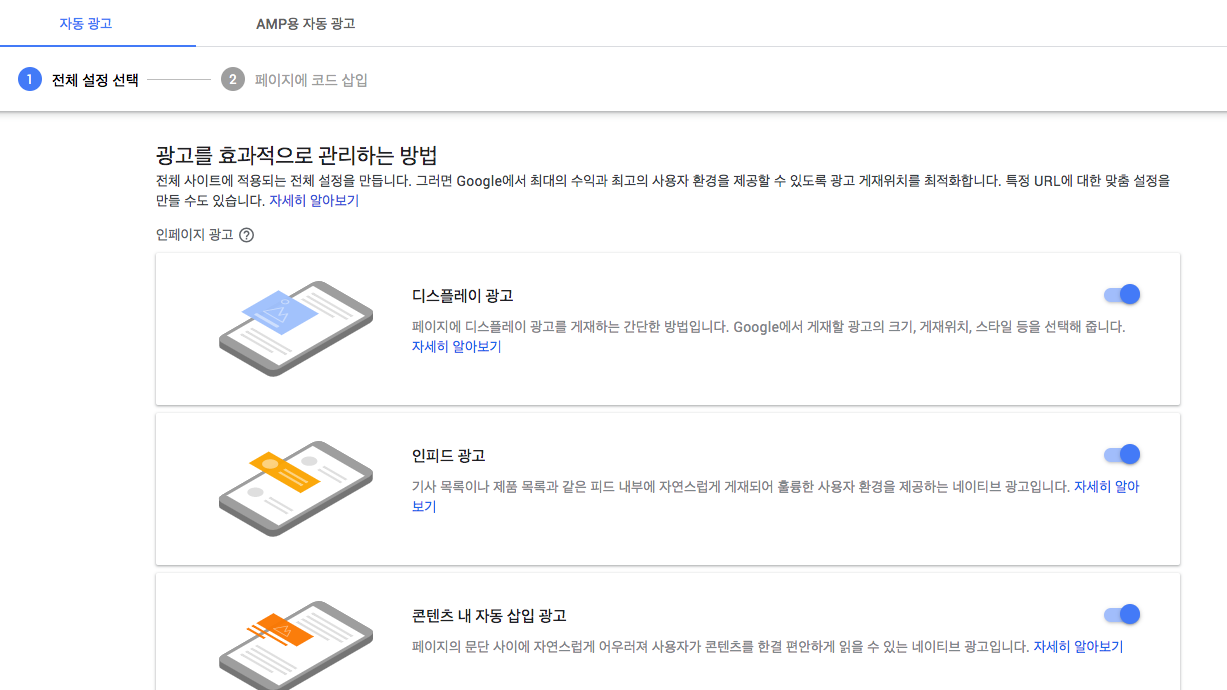
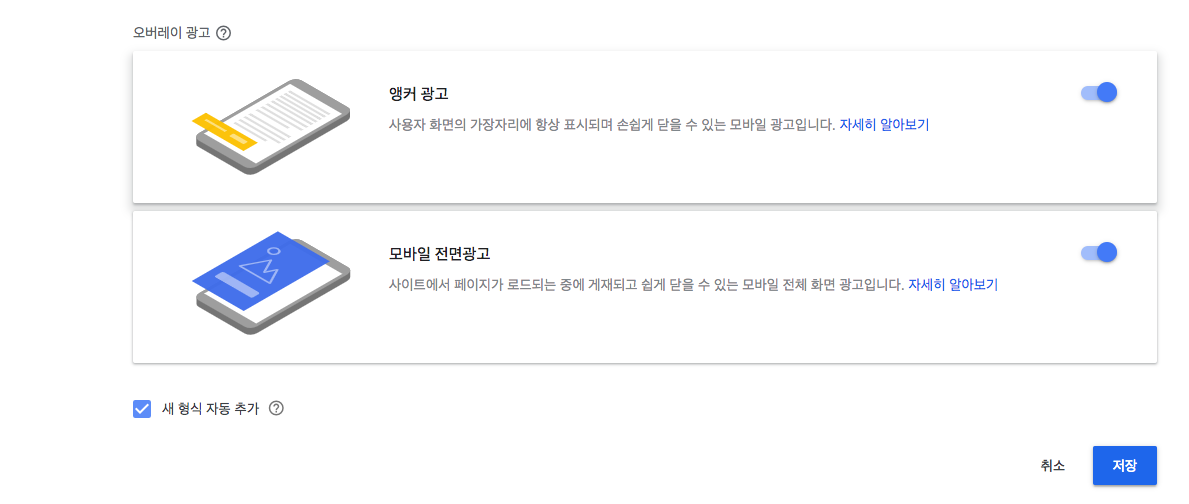
- 일단 기본값으로 모든 항목에 체크되어 있어서 그대로 진행하였습니다.
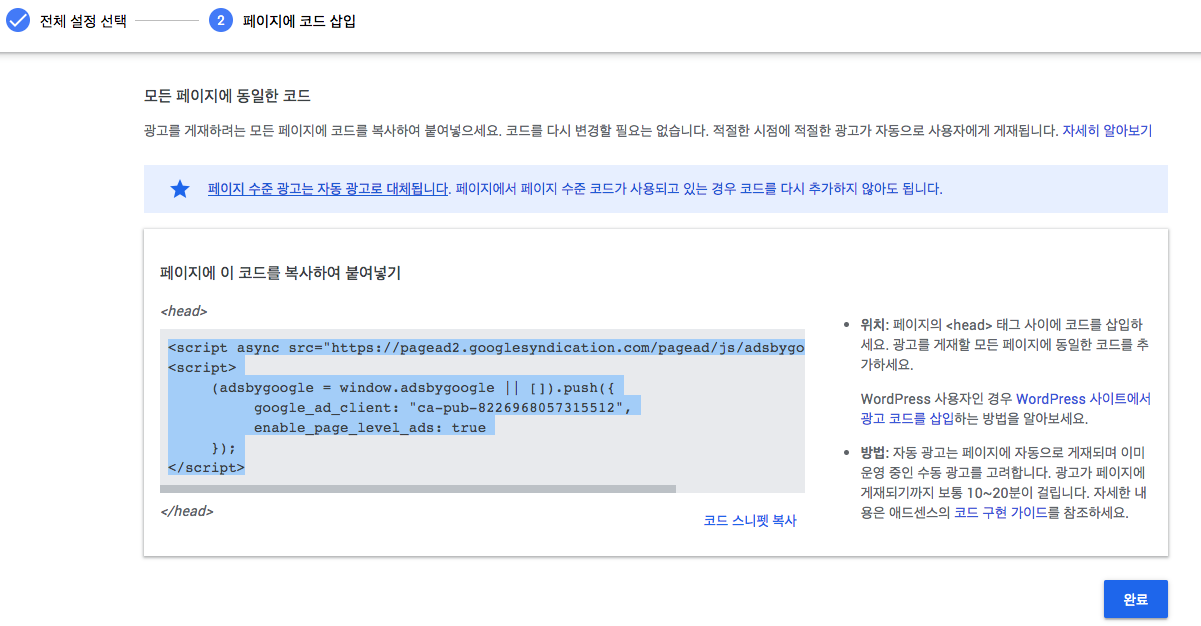
- 위 코드 역시 지난번 Google Adsense 등록할 때
google_adsense.ejs파일을 생성하고_layout.swig에 추가했던 내용과 동일한 것으로 너무 편하게(?) 완료를 누리시면 됩니다.
- 순식간에 끝나버렸습니다…ㅎ
광고 단위 설정
- 광고 단위 탭을 누르면 다음과 같은 화면이 나옵니다.
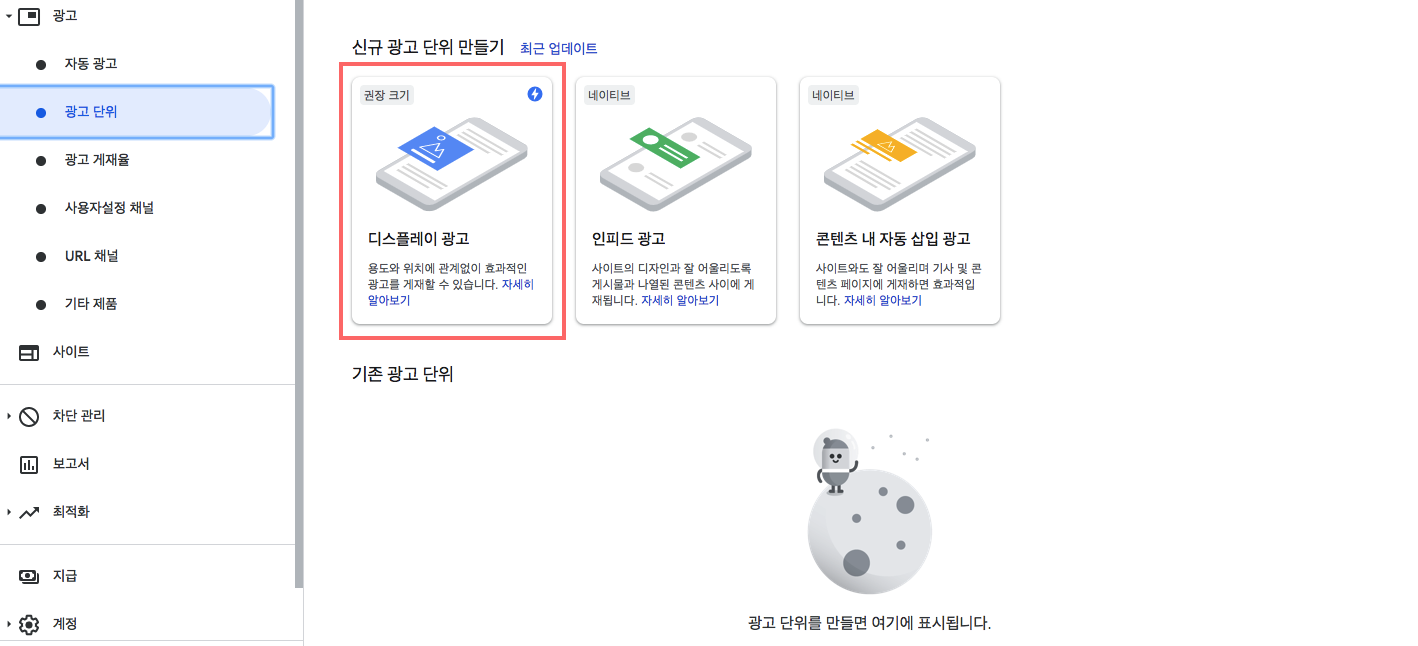
- 우선 저는 사이드바에 ‘디스플레이 광고’ 를 게제할 생각입니다.
디스플레이 광고에는 3가지 유형이 있습니다.
- 사각형
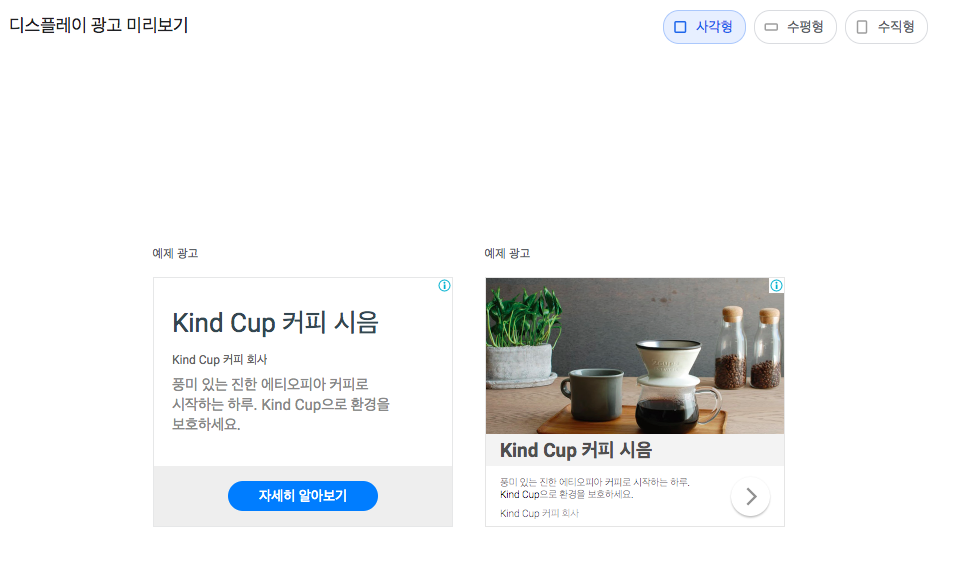
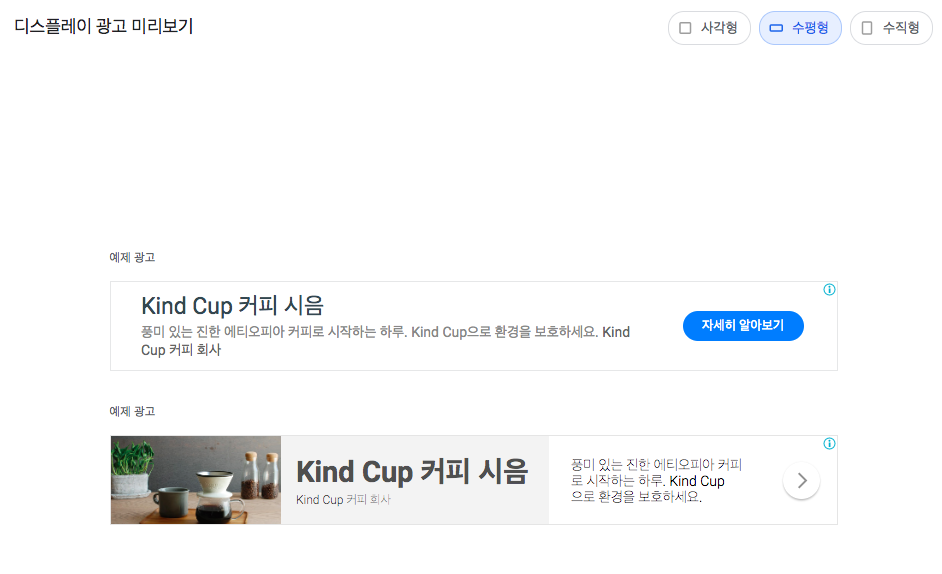
- 수평형
- 수직형
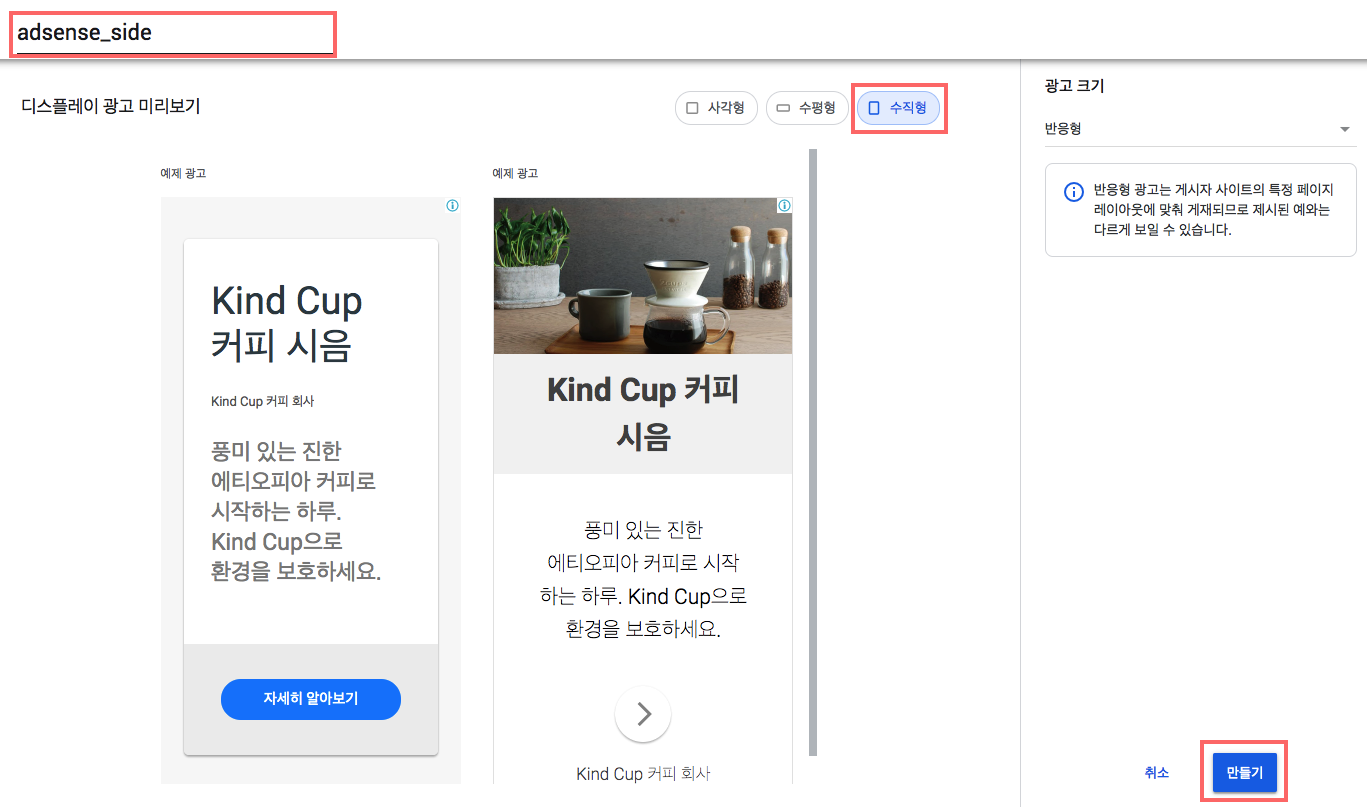
- 저는 수직형을 선택하여 진행하였습니다. 좌측 상단의 광고 단위 이름 을 지정하고 만들기를 누르시면 됩니다.
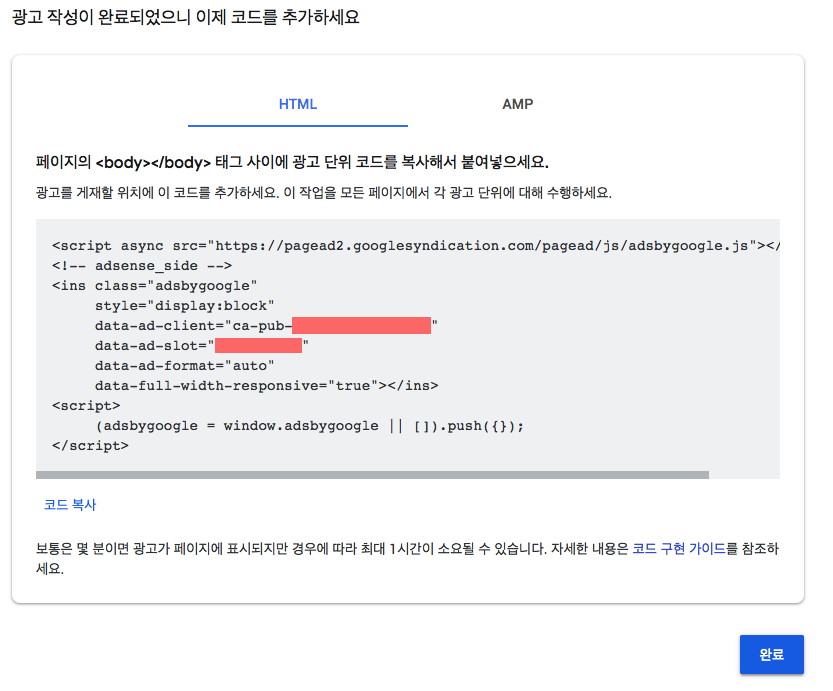
마지막으로 소스 코드를 블로그 layout에 추가해 주시면 되겠습니다.
ejs파일을 생성하는 방법과swig파일을 생성하는 방법 2가지가 있습니다. (두 파일의 차이점은 아직 잘 모르겠습니다.)ejs템플릿 엔진으로 광고를 게제하는 방법은 이전에 구글 애드센스를 처음 신청할 때 했던 방법과 비슷합니다.adsense_side.ejs파일을 생성하여 위 소스 코드를 넣어 놓고,\_marco디렉토리 안의_sidebar.swig파일에(끝에 추가하시면 됩니다) 적용하시면 됩니다.이번에는 색다르게
swig파일을 생성하고 적용하여 보겠습니다.
먼저\_third-party디렉토리에\ad라는 폴더를 생성하겠습니다. 생성한 폴더에ads_side.swig라는 파일을 생성하고 여기에 소스 코드를 복사/붙여넣기 하시면 됩니다.
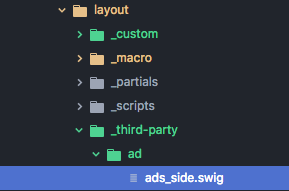
- 앞선
ejs방법과 똑같이\_marco디렉토리 안의_sidebar.swig파일에(끝에 추가하시면 됩니다) 아래 사진에 적힌 것 처럼 작성해 주시면 됩니다.
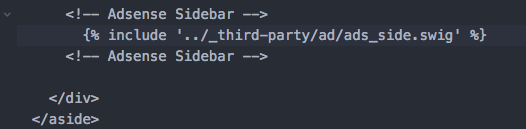
hexo g -d를 통해 블로그에 배포하시고 대략 30분 정도 지나면 적용된 것을 확인하실 수 있습니다.
디스플레이 광고 이외에도 다른 광고들은 비슷한 방식으로 적용하시면 되겠습니다. 혹시 나중에 기회가 된다면 따로 포스팅 하겠습니다.
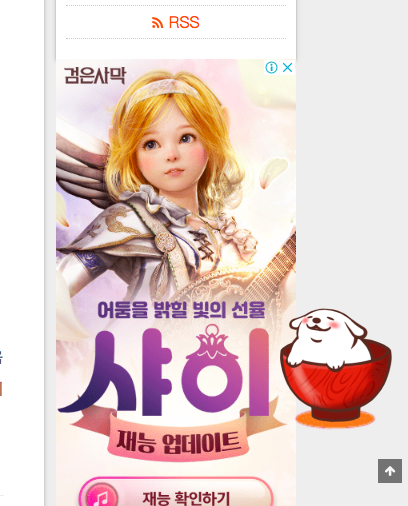
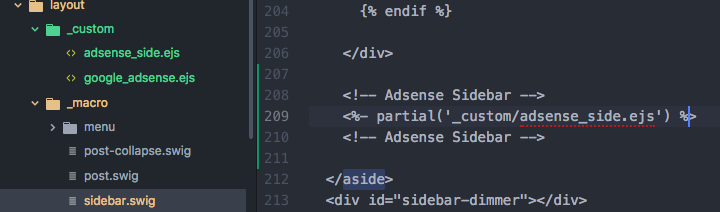
- partial과 include 의 차이점을 아직 잘 모르겠지만… 주의하실 점은
- 경로를 상대 경로로 지정해 주어야 하는점
../custom/adsense_side.ejs(못 읽으면 아래 사진 처럼 나오는 것 같습니다.) - sidebar 전체
<div>태그 안에 광고를 넣어야 scroll 시 화면 따라 광고도 움직입니다.