기존 테마가 별로 마음에 안 들어서 새로운 테마로 바꾸게 되었다.
(파이썬) 01 HELLO, PYTHON!
Reference
- Kaggle 홈페이지 - Kaggle
- 1강 ‘Hello, Python’ - Python Micro-Course Home Page
개요(Intro)
Data Science에 필요한 Python의 핵심적인 부분들을 배우는 과정입니다. 본 과정은 기초적인 코딩 경험이나 지식이 있는 사람들을 대상으로 작성되었습니다. (만약 코딩에 익숙하지 않으시다면 “Python for Non-Programmers“ 해당 문서를 참고하는 것을 권장합니다)
우선, Python의 구문(syntax), 변수 할당(variable assignment), 산술 연산자(arithmetic operators)에 대해 가볍게 다루어 보겠습니다. 만약 Python에 경험이 있으시면 바로 연습문제(exercise with Kaggle Kernal)로 넘어가셔도 됩니다.
Hello, Python!
Python 은 영국의 코미디 그룹 몬티 파이선(Monty Python)에서 그 이름을 가져왔습니다. 그들에게 존경을 표하는 마음으로 우리의 첫 python 프로그램을 스팸(spam)에 관한 그들의 코미디 스케치(skit)를 만들어 볼까요?몬티 파이선의 코미디 스케치 25화 7분 50초부터 해당 에피소드가 등장한다고 합니다 - youtube 영상
그저 재미로, 아래의 코드를 읽어보시고 어떻게 실행 될지 예상해 보세요.
spam_amout = 0 |
결과는 아래와 같습니다
0 |
자, 이제 하나하나 분석해보겠습니다. 이 간단한 프로그램은 파이썬 코드가 어떻게 생겼는지, 어떻게 동작하는지를 여러 중요한 측면들을 통해 보여줍니다. 위에서 부터 순서대로 살펴보겠습니다.
spam_amount = 0 |
변수 선언 : spam_amount라는 변수를 만들고 할당 연산자라고하는 = 을 사용하여 0 값을 할당합니다.
잠깐! : 만약 기존에 다른 언어(Java 또는 C ++ 등)로 프로그래밍을 하셨던 분의 경우 파이썬 코드에서는 몇 가지 빠져있는 것을 느꼈을 것 입니다.
spam_amount를 할당하기 전에 “선언(declar)”할 필요가 없습니다.
우리는 파이썬에게 어떤 유형의 값인spam_amount가 참조 할지를 말할 필요가 없습니다. 사실, 우리는 문자열(string)이나 부울(boolean)과 같은 다른 종류의 것을 참조하기 위해spam_amount를 재할당 할 수 있습니다.
print(spam_amout) # 0 |
함수 호출 : print 함수는 화면에 전달 된 값을 표시하는 파이썬 함수입니다. 함수 이름 뒤에 괄호를 넣고 그 괄호 안에 입력 (또는 인자)을 넣음으로써 함수를 호출합니다.
#스팸, 계란, 스팸, 스팸, 베이컨과 스팸 주문 |
첫 줄은 주석(comment) 입니다.파이썬에서는 # 기호로 시작하면 주석으로 처리합니다.
다음으로 우리는 재할당(reassignment)의 예를 볼 수 있습니다. 기존 변수의 값을 재할당하는 것은 변수를 만드는 것과 똑같은 것처럼 보입니다. <- 여전히 할당 연산자 = 을 사용합니다.
이 경우 spam_amount에 지정하는 값으로 이전 값에 대한 간단한 산술 연산을 한 값을 할당합니다. 파이썬은 (0 + 4 = 4)에서 = 오른쪽에있는 표현식의 값을 왼쪽에있는 변수에 할당합니다.
if spam_amount > 0: |
조건문(conditional)에 대한 설명은 나중에 자세히 다루겠지만, 코드를 전혀 짜본적 없더라도 이 문장이 어떤 것을 의미하는지는 짐작할 수 있을 것 입니다. 파이썬은 가독성과 단순성 때문에 높이 평가됩니다.
어떤 코드가 if문에 속해 있는지 구별하는 방법을 잘 보십시오. "But I don't want ANY spam!" 문자열은 spam_amount가 양수일 때만 출력되어야 합니다. 하지만 뒤에 print (viking_song)과 같은 코드는 무슨일이 있어도 실행 되어야합니다. 우리(그리고 파이썬)는 그것을 어떻게 알 수 있습니까?
if문 줄(line)의 끝에있는 콜론 (:)은 새로운 “코드 블록”이 시작되고 있음을 나타냅니다. 들여 쓰기되는 후속 행이 해당 코드 블록의 일부 입니다. 다른 언어에서는 { 중괄호 }를 사용하여 코드 블록의 시작과 끝을 표시합니다. Python의 이런 공백을 사용한 코드 블럭은 다른 언어에 익숙한 프로그래머에게는 놀라운 일일 수 있지만, 코드 블록의 들여 쓰기를 시행하지 않는 언어보다 일관되고 읽기 쉬운 코드가 될 수 있습니다.
이후의 행에서 viking_song을 다루는 줄은 여분의 4 칸으로 들여 쓰이지 않기 때문에 if의 코드 블록에 포함되지 않습니다. 나중에 함수를 정의하고 루프(loops)를 사용할 때 들여 쓰기 된 코드 블록의 예제를 보게 될 것입니다.
이 스니펫은(snippet)은 파이썬에서의 문자열(string) 형태 입니다.
"But I don't want ANY spam!" |
문자열은 큰 따옴표 나 작은 따옴표로 표시 할 수 있습니다. (예제의 문자열에는 작은 따옴표가 포함되어 있으므로 파이썬이 혼동하는 것을 방지하기 위해 큰 따옴표를 사용했습니다.)
viking_song = "Spam " * spam_amount |
*연산자는 두 개의 숫자를 곱하는데 사용되기도 하지만(3 * 3은 9로 계산됩니다), 문자열에 숫자를 곱하여 그 수만큼 반복되는 문자열을 만들 수도 있습니다. 파이썬에서 *와 + 같은 연산자는 어디에 적용되는지에 따라 이와 같이 많은 시간 절약 트릭을 제공합니다. (참고: operator overloading)
파이썬에서의 수와 산술(Numbers and arithmetic in Python)
위 예제를 통해 우리는 숫자 값을 가지는 변수를 이미 보았습니다.
spam_amout = 0 |
변수형(type)을 “Number” 라고 표현하기보다 좀 더 전문적인 표현을 원한다면 우리는 파이썬에게 spam_amout 의 type을 물어볼 수 있습니다.
type(spam_amout) # int |
변수가 ìnt 형 (short for integer) 임을 알 수 있습니다. 파이썬에는 이 외에도 다른 형태의 숫자형이 있습니다
type(19.95) # float |
float형은 소수점 이하의 숫자를 나타냅니다 - 가중치(weight)나 비율(proportion)을 나타낼 때 유용합니다.
type() 함수는 위에서 다뤘던 print() 함수 이후 두번째로 만나는 내장 함수이며 기억해두시면 좋습니다. 이 함수를 통해 파이썬에게 “이 함수의 형태가 무엇인지?”를 묻고 답을 얻을 수 있습니다.
숫자(number)를 다룬다면 빠질 수 없는게 산술(arithmetic)입니다. 우린 이미 + 더하기 연산과, * 곱하기 연산을 위에서 살펴 보았습니다(sort 함수). 파이썬에는 계산기에서 볼 수 있는 기본적인 연산을 지원합니다.
| Operator | Name | Description |
|---|---|---|
a + b |
Addition | Sum of a and b |
a - b |
Subtraction | Difference of a and b |
a * b |
Multiplication | Product of a and b |
a / b |
True division | Quotient of a and b |
a // b |
Floor division | Quotient of a and b, removing fractional parts |
a % b |
Modulus | Integer remainder after division of a by b |
a ** b |
Exponentiation | a raised to the power of b |
-a |
Negation | The negative of a |
하나의 흥미로운 사실은 계산기에는 나누기 버튼이 하나만 있는 반면 파이썬에는 두 가지 종류로 구분되어 있습니다. “True division”이 우리에게 익숙한 기본적인 나눗셈 연산을 수행합니다.
print(5 / 2) # 2.5 |
결과는 항상 float 형으로 반환됩니다.
// 연산은 나눗셈 된 값을 반올림 한 정수값을 결과로 반환합니다.
print(5 // 2) # 2 |
위 연산이 유용하게 쓰일만한 상황이 떠오르시나요? 곧 예제를 통해 살펴보도록 하겠습니다.
연산 순서(Order of operations)
초등학교에서 다들 산술 연산의 연산 순서 대해 배우셨을겁니다. 외국에서는 PEMDAS - Parentheses, Exponents, Multiplication/Division, Addition/Subtraction 로 외우나 봅니다 괄호 ->지수 -> 곱셈 /나눗셈 -> 덧셈 /뺄셈 순서로 계산하면 된다고 기억하실겁니다.
파이썬에서도 비슷한 규칙으로 계산을 합니다. 그리고 매우 직관적입니다.
8 - 3 + 2 # 7 |
기본적인 연산만으로는 우리가 원하는 결과를 얻지 못할 경우도 생깁니다.
hat_height_cm = 25 |
이 경우 괄호(parentheses)를 사용하면 되겠습니다. 괄호를 사용하면 하위 표현식(sub-expression)을 먼저 계산할 수 있도록 연산의 순서를 조절할 수 있습니다.
total_height_meters = (hat_height_cm + my_height_cm) / 100 |
연산 관련 내장함수(Builtin functions for working with numbers)
min과 max 는 각각 최소값과 최대값을 반환합니다.
print(min(1, 2, 3)) # 1 |
abs는 절대값을 반환합니다.
print(abs(32)) # 32 |
int와 float를 사용해서 각자의 형태(type)로 변환이 가능합니다.
print(float(10)) # 10.0 |
연습문제(Your Turn)
학습한 내용을 연습해 보세요. first Python programming exercise
운영체제 - Overview_2
컴퓨터 시스템 구조
2.1 컴퓨터 시스템의 동작

- 컴퓨터는 공유된 주기억장치에 접근을 제공하는 공통 버스에 의해 연결된 CPU와 여러 개의 장치 제어기(Device controller)로 구성되어 있습니다.
- 장치 제어기(Device Controller)
각 장치(디스크, 오디오 장치, 비디오 디스플레이)를 관리 - 장치 제어기와 CPU는 병행으로 수행되므로 이들은 주기억장치 접근에 대해 경쟁합니다. 주기억장치 제어기(Memory Controller)는 이들의 접근을 동기화해줍니다.
- 장치 제어기(Device Controller)
- 컴퓨터가 처음 구동되면 초기에 실행될 프로그램이 필요합니다. 이 프로그램을 부트스트랩 프로그램(Bootstrap program) 이라고 합니다. 이 프로그램은 보통 컴퓨터 하드웨어 내에 ROM(Read-Only-Memory)에 저장되어 있습니다.
- 부트스트랩 프로그램(Bootstrap program)
모든 하드웨어를 초기화하고 운영체제 커널을 주기억장치에 적재한 후에 커널을 실행
- 부트스트랩 프로그램(Bootstrap program)
- 컴퓨터에서 사건(Event)의 발생은 인트럽트(interrupt) 신호, 트랩(trap) 혹은 예외(Exception) 를 통해 운영체제에 통보됩니다. 사건이 발생되면 CPU는 현재 수행중인 작업을 멈추고, 운영체제 내에 있는 특정 코드를 실행합니다. 이 실행이 끝나면 다시 멈춘 작업을 재개합니다.

Interrupt
- Hardware Interrupt : 하드웨어는 CPU에 특정 신호를 보내어 인트럽트의 발생을 알림
– 예) 키보드 입력, I/O interrupt, timer ticks - 하드웨어가 시스템의 수행 흐름을 바꾸기 위해 발생하는 것
- 비동기식(Asynchronus Interrupt)
Trap
- Software Interrupt : 시스템호출(System call)이라는 특정 연산을 실행하여 일부로 발생시키거나 오류 때문에 자발적으로 발생
– 오류의 예) 0 나누기, 부적합한 주기억장치 접근(page fault) - 동기식(Synchronus Interrupt)
Exception
- 프로세서에 의해 자동으로 처리
- Faults 와 Aborts 로 세분화 가능
– Faults : 복구 가능한 오류 (recoverable error)
– Aborts : 처리하기 어려운 오류 (an error that is difficult to handle)
2.2 I/O 구조
- 장치 제어기(Device controller)에 따라 하나 이상의 장치가 제이거에 연결될 수 있습니다
- 장치 제어기는 지역 버퍼와 몇 개의 특수 목적 레지스터를 유지합니다
- 장치 제어기는 연결된 주변장치와 지역 버퍼 간에 데이터 이동을 책임집니다. 이 버퍼의 크기는 주변장치에 따라 다릅니다.
2.2.1 I/O Interrupt
- 입출력의 두 가지 형태
– 동기식 입출력(Synchronous I/O) : 입출력이 시작되면 요청한 프로세서는 입출력이 완료될 때까지 기다림
– 비동기식 입출력(Asynchronous I/O) : 요청한 프로세서는 입출력이 완료될 때까지 기다리지 않고 계속 다른 작업을 수행 - 입출력의 완료를 기다리는 방법
– 특수한 명령어 사용
– 대기 루프 사용 - 만약 CPU가 입출력 완료를 항상 기다리면 한번에 한 입출력만 가능
하지만 시스템의 효율을 높이기 위해 입출력과 계산을 병행할 수 있어야함으로 이 방법은 비효율적 - 운영체제는 여러 개의 입출력 요청을 관리하기 위해 장치 상태 테이블(device-status table) 을 유지합니다. 각 장치마다 대기큐를 유지합니다.
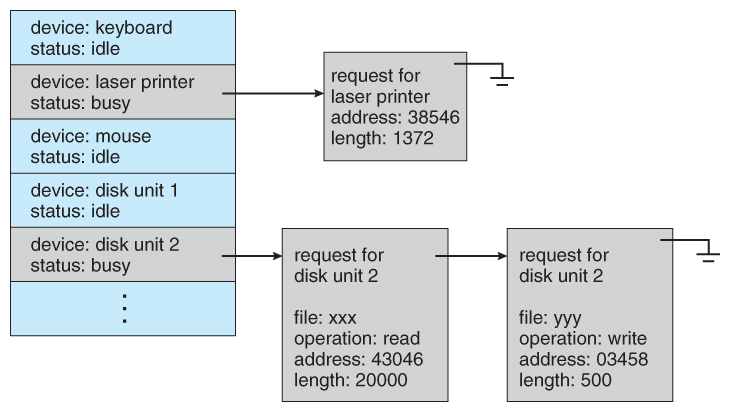
2.2.2 DMA 구조
- 속도가 느린 입출력 장치는 하나의 입력을 받은 후에 다음 입력까지 CPU는 다른 유용한 작업을 할 수 있습니다.
반대로 속도가 빠른 입출력 장치는 인트럽트가 너무 빈번하게 발생하여 CPU가 다른 유용한 작업을 할 시간이 없습니다. - 이것을 해결하기 위해 사용하는 기법이 DMA(Direct Memory Access) 입니다.
- DMA 방식에서 장치 제어기는 데이터 블록을 CPU의 관여없이 직접 주기억장치로 이동하며, 인터럽트는 바이트 단위가 아닌 블록 단위로 발생합니다.

2.3 저장 구조

컴퓨터 프로그래밍이 실행되기 위해서는 주기억장치(main memory / primary storage / internal memory) 에 적재되어야 합니다
주기억장치는 보통 동적 임의접근 메모리(dynamic Random-Access Memory, RAM)라고 하는 반도체 메모리를 사용
CPU가 직접 접근할 수 있는 기억장치는 주기억장치뿐입니다
주기억장치의 한 구성 단위를 워드(word) 라 하며, 각 워드는 독특한 주소를 가집니다
주기억장치의 크기 / 주기억장치의 휘발성 때문에 모든 프로그램과 데이터를 주기억장치에 영구적으로 저장할 수 없습니다
이 문제를 해결하기 위해 많은 양의 데이터를 영구 보관할 수 있는 보조 기억장치(auxiliary memory / secondary storage / external memory) 를 사용합니다
2.3.1 주기억장치
- Memory-mapped I/O
주기억장치의 일부 주소가 입출력을 위해 예약되어 있으며, 이 주소에서 읽거나 쓰면 장치 레지스터로부터 데이터를 읽거나 쓰는 결과가 되는 것 - CPU가 I/O 포트를 통해 연결된 장치와 데이터를 교환하는 2가지 방식
– Programmed I/O : CPU가 계속 장치의 상태를 검사(polling)하는 방식
– Interrupt : 다음 데이터를 처리할 준비가 되면 장치 제어기는 인터럽트를 통해 그 사실을 CPU에 알리는 방식 - 주기억장치와 CPU의 속도 차이를 극복하기 위해 주기억장치와 CPU 사이에 캐시(cache) 라고 하는 고속 메모리 버퍼를 사용
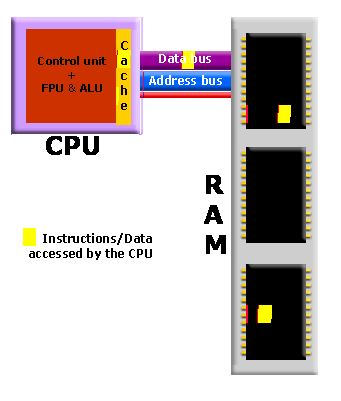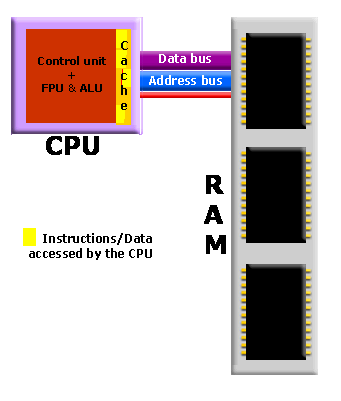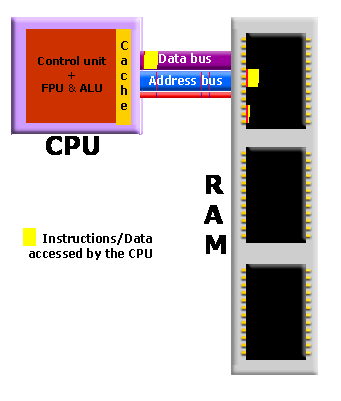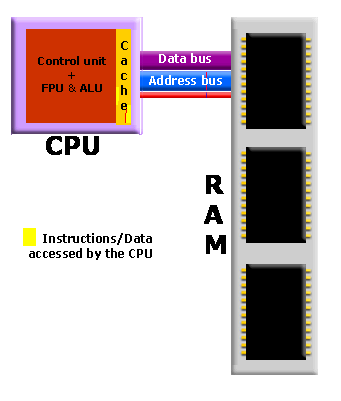
2.3.2 보조기억장치(자기 디스크)
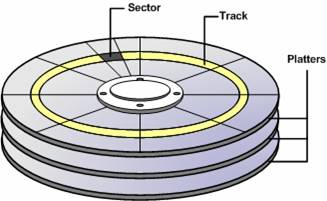
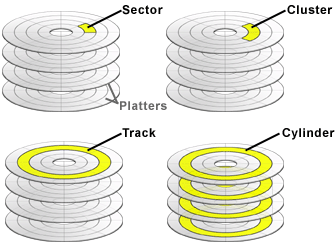
자기 디스크는 플래터(platter) 라고 하는 여러 개의 원형 판으로 구성이 플래터는 다시 원형 모양의 트랙(track) 으로 구성
트랙은 다시 여러 개의 섹터(sector) 로 나뉘어짐
![]()
단순하게 섹터를 여러 개를 하나로 묶은 것을 클러스터(cluster) 라 하고, 같은 위치에 있는 트랙의 모음을 실린더(cylinder) 라고 합니다
– 클러스터는 운영체제에서 사용하는 데이터 저장의 최소 단위
디스크의 속도 = 컴퓨터로 데이터를 전송하는 비율인 전송률(transfer rate) + 임의접근 시간(random-access time)이라고 하는 위치결정 시간(positioning time)에 의해 결정됩니다
데이터의 교환은 특수한 제어기를 통해 이루어집니다
컴퓨터 연결 끝에는 호스트 제어기
디스크 자체 내에는 디스크 제어기 가 있습니다디스크 제어기는 자체적으로 캐시를 가지고 있습니다
실제 데이터는 디스크 제어기에 의해 디스크에서 캐시로 옮겨지고, 호스트 제어기는 캐시에 있는 데이터를 주기억장치로 옮깁니다
2.4 저장장치의 계층구조
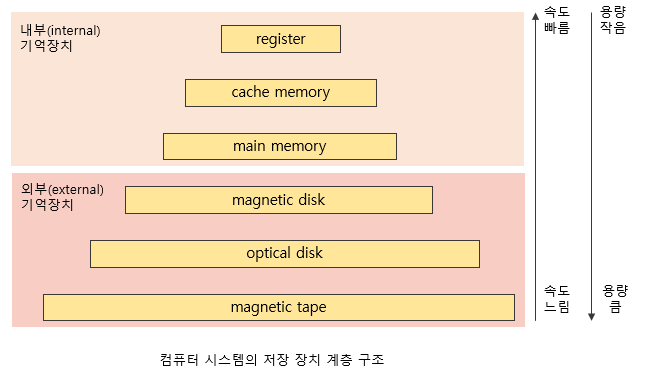
- 계층구조에서 위에 위치할 수록 속도는 빠르지만 고가이며 휘발성의 성질을 가집니다
- 두 저장장치의 속도 차이는 중간에 빠른 캐시를 설치하여 극복할 수 있습니다
- 시스템을 구성할 때 저장장치의 계층구조를 균형있게 잘 구성하면 저렴한 가격에 높은 성능을 얻을 수 있습니다
2.4.1 캐싱
- CPU가 데이터를 필요하면 먼저 캐시에 그 데이터가 있는지 검사합니다
만약 있으면 캐시에서 바로 사용하고 없으면 주기억장치에 있는 데이터를 사용하지만 이 데이터의 복사본을 캐시에 보관합니다. 이는 데이터를 곧 다시 사용할 확률이 높기 때문입니다 - 캐시의 크기는 제한 되어 있으므로 이것을 잘 관리하여야 시스템의 성능을 높일 수 있습니다. 캐시의 크기와 교체 정책(replacement policy)을 잘 선택하면 원하는 데이터가 캐시에 있을 확률을 80%에서 99%까지 높일 수 있습니다
- 주기억장치는 CPU와 보조기억장치 사이에 있는 캐시로 사용될 수 있습니다
2.4.2 일관성
- 저장장치의 계층구조를 사용하면 같은 데이터가 여러 레벨에 존재할 수 있습니다
- 한번에 하나의 프로세스만 동작하면 아무 문제가 되지 않지만!
여러 프로세스가 같은 데이터를 접근하고자 하면 모든 프로세스가 최신의 데이터를 얻을 수 있도록 해야 합니다
이 문제는 다중프로세서 시스템에서 더욱 심각합니다 - 분산 환경에서는 여러 파일의 복사본이 여러 컴퓨터에 분산되어 있을 수 있습니다. 따라서 하나의 복사본에 대한 갱신이 이루어지면 다른 복사본도 갱신되도록 하여야 합니다
Reference
Difference between Trap and Interrupt
DMA-CPU몰래 영차영차